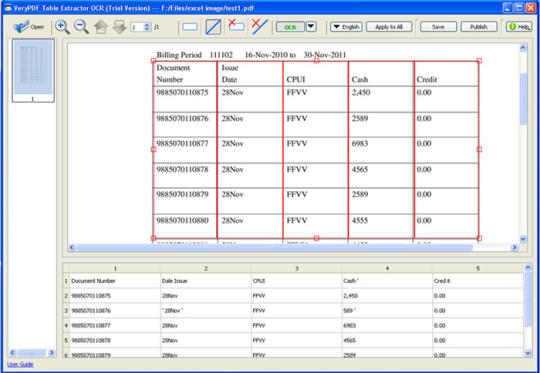
VeryPDF Table Extractor OCR är en användbar och kraftfull applikation som är att utvinna tabeller från skannas, normal PDF eller bild och sedan känna igen tecknen i PDF eller bild i olika språk med OCR-teknik. Det stöder att rita linjer för att erkända karaktärer och bildar ny tabell.
a. Utdrag tabell från skannade eller normal PDF-dokument
VeryPDF Tabell Extractor OCR stöder att extrahera tabeller från normal PDF eller skannade PDF-dokument med optisk teckenigenkänning teknik med hög effektivitet och kvalitet. I den extraherade tabellen, kan du också lägga till eller ta bort vertikala linjer efter dina behov.
b. Räta och bort fläckar ingång PDF-dokument
VeryPDF Tabell Extractor OCR gör det möjligt att räta upp den ingående PDF-dokumentet om det är en skev en i intervallet 15 graders. Det stöder också att avlägsnar du fläckar de PDF-dokument som är fulla av prickar och fläckar genom att använda rena verktyg och skapa ett nytt rent dokument äntligen.
Dragen av VeryPDF Tabell Extractor OCR:
1. Stöd för flera språk.
2. Stöd online-publicering.
3. Mata filformat: PDF, BMP, JPG, JPEG, JPE och GIF.
4. Utgångs filformat: CSV, XLS, HTML, pptx, docx, xlsx, RTF och TXT.
5. Använd regeln för den nuvarande sidan till alla de övriga sidorna.
6. Markera motsvarande originaltexten när klicka på texten på de viktigaste gränssnittet.
7. Ändra färg på indatafiler i svart- och- vita genom att ändra tröskelvärdet.
8. räta automatiskt ingångsfilen när den skeva vinkeln är mindre än 15 graders.
Kommentarer hittades inte